The Cyber World is the Wild West!
Cybersecurity is becoming increasingly important in this day and age. More attacks are happening, with the attacks becoming more sophisticated to the point that simple detection systems are no longer adequate to defend against them.
Criminal entities launch cyber attack on websites to:
-
Compromise an account (i.e. stealing a user’s login credentials) - these can then be used to steal data, money or for other illegal activities
-
Create fake accounts for further criminal acts (e.g. creating fake email accounts to create accounts on a website to get free gift cards)
-
Feed bad information to AI to poison their databases (e.g. Bing AI). User input and feedback is an important part of the ML training dataset, and bad inputs in turn poisons and corrupts the underlying AI model. I discuss more about this ML poisoning phenomenon in my prior ML poisoning blog post.
Many of these attacks are launched via sophisticated botnets (using machine learning).
Fortunately, a way to defend against these cyber attacks is fingerprinting. That is, if we can identify which devices/traffic are from bad actors, we can just block these traffic sessions. This means good/legitimate traffic is still allowed through, but bad actors are thwarted and blocked.
I will discuss some cybersecurity methods of fingerprinting and identifying whether a device/traffic is a bad actor:
- Simple Fingerprinting
- Canvas Fingerprinting
- TLS and HTTP/2 Fingerprinting
- Device Fingerprinting
- Traffic Pattern Fingerprinting
- Behavioural Biometric Fingerprinting
 Image by Gerd Altmann from Pixabay
Image by Gerd Altmann from Pixabay
What is a botnet attack?
A botnet is a network of devices (i.e. bots) that are coordinated by a single attacker to launch coordinated cyber attacks. Often the bots are everyday devices infected with malware, where the owner has no idea their device is infected (or even being used in a cyber attack). When a device is infected it is known as a ‘zombie’.
The scale of a botnet can be massive, with some attacks using hundreds of millions of infected devices, ranging from IoT devices (such as smart devices), mobile phones to computers. The bots automatically attack a target with no human intervention needed.
For example, Cloudflare was hit by a distributed denial-of-service (DDoS) attack via botnets, which involved 71 million requests per second. The attack involved over 30,000 source IPs!
 Photo by Kindel Media
Photo by Kindel Media
Another common example of a botnet attack is a ‘dictionary attack’ to compromise a user’s login credentials. Essentially, the bots will keep trying logging into an account with passwords from a ‘dictionary database’. This database is often a list of real known passwords stolen from another hack.
Botnet attacks generally use headless web browsers. These are command-line based browsers (that don’t have a UI) that can be used for large-scale automated attacks on websites.
Many of these botnet attacks use sophisticated methods of machine learning to circumvent anti-bot systems. They employ advanced methods to learn how to mimic the behaviour and signatures of legitimate users and devices. If the detection system is too rudimentary, it won’t be able to differentiate between human vs bot.
How Fingerprinting works
Fingerprinting in the context of cybersecurity is the process of assigning an unique identifier to a user/device. Using this fingerprint can help identify legitimate users (i.e. whitelist) or identify bad actors (i.e. blacklist). The core principle is you want to let legitimate users in, while keeping bad actors out.
How this works is you assign a risk score against every single user/device that attempts to access the website, based on the results of the fingerprinting system. For example, if it is a complete match against a known whitelisted user/device, then the risk score is low, while if it is a partial match then the risk score would be higher. If there is no match to any known fingerprint, then the risk score is high.
The converse can also be true: if there is a complete match against a known bad actor, then the risk score is high.
 Image by Gerd Altmann from Pixabay
Image by Gerd Altmann from Pixabay
1. Simple fingerprinting using session cookies, IP and email addresses
Simple fingerprinting techniques do not use any sophisticated methods to identify a user, but instead rely on one attribute that can identify or be linked to a user. Three of the method common attributes are session cookies, IP addresses and email addresses.
Session cookies are small files that are stored on a user’s web browser when they visit a website. These track the user’s activity on that site - for example, if you log in to amazon.com.au, you don’t need to re-login when you visit again later.
These are very simple to thwart by clearing the cookies from your browser or use Incognito/Private mode (so cookies from your session aren’t permanently stored and deleted after you close the browser).
Similarly, IP and email fingerprinting relies on tying an IP/email to a particular user. In some cases, IP addresses can even be used to link traffic to a known data centre or VPN. Generally speaking, major cloud providers and data centres (e.g. CloudFlare, AWS), as well as VPN providers, have a known list of IP ranges that they use for their outgoing traffic.
A decent IP fingerprinting system will be able to identify whether traffic is coming from a known VPN or data centre. Similarly, a decent email fingerprinting system will keep a list of email addresses that either are confirmed compromised or potentially compromised (e.g. emails from a data leak). In both these cases, traffic from these sources will be rated more risky.
 Photo by panumas nikhomkhai from Pexels
Photo by panumas nikhomkhai from Pexels
However, these fingerprinting methods are easy to bypass, as IP rotating services (via proxy servers) (e.g. OxyLabs) can allow attackers to use 100% clean IP addresses. Bypassing email fingerprinting is generally done by creating thousands of newly minted email accounts to launch one-off attacks.
Therefore, these fingerprinting techniques alone are not effective today in stopping cyber attacks. They need to be combined with more advanced methods (like as described below).
2. Canvas Fingerprinting
Canvas fingerprinting (CFP) is a browser fingerprinting technique using the HTML5 canvas element. Unlike simple fingerprinting techniques, a user cannot just ‘delete’ their canvas fingerprint, as it is tied to the physical characteristics of their device.
CFP is a very common technique used by websites to track users and serve tailored advertising - I discussed this in my prior blog on how Google advertising works.
How CFP works is each unique device configuration will draw the HTML5 canvas element slightly differently due to tiny differences in the underlying physical hardware (i.e. CPU, iPhone version), as well as software differences (e.g. operating system).
You can see your own canvas fingerprint via Mozilla’s website: https://amiunique.org/.
For example, this is my device’s canvas fingerprint:
 You can see that less than 0.01% of total devices have the same CFP as my device
You can see that less than 0.01% of total devices have the same CFP as my device
However, there are a few major drawbacks of CFP:
-
It cannot identify users, but only devices, as a device can in theory have multiple users (e.g. family PC). Therefore, victims of zombie bots may find their traffic blocked if their device was used to attack a particular website.
-
Browsers like Brave use differential privacy to randomise some of the above factors so every time a user visits a web page, their fingerprint is slightly different. You can read more about it here.
-
Open-source technology exists can generate fake canvas fingerprints - e.g. via puppeteer.
-
Headless browsers can be configured to not send data on many browser/device fingerprinting fields or deliberately not render any images on the website (therefore bypassing CFP).
3. TLS and HTTPS/2 Fingerprinting
TLS fingerprinting is a fingerprinting technique that uses the characteristics of the connection between the web server and the client device. In essence, whenever a device securely connects to a website (i.e. using HTTPS or https://), the device needs to create a secure connection with the web server.
The encryption protocol used is generally Transport Layer Security (TLS). You can see this in the below screenshot:
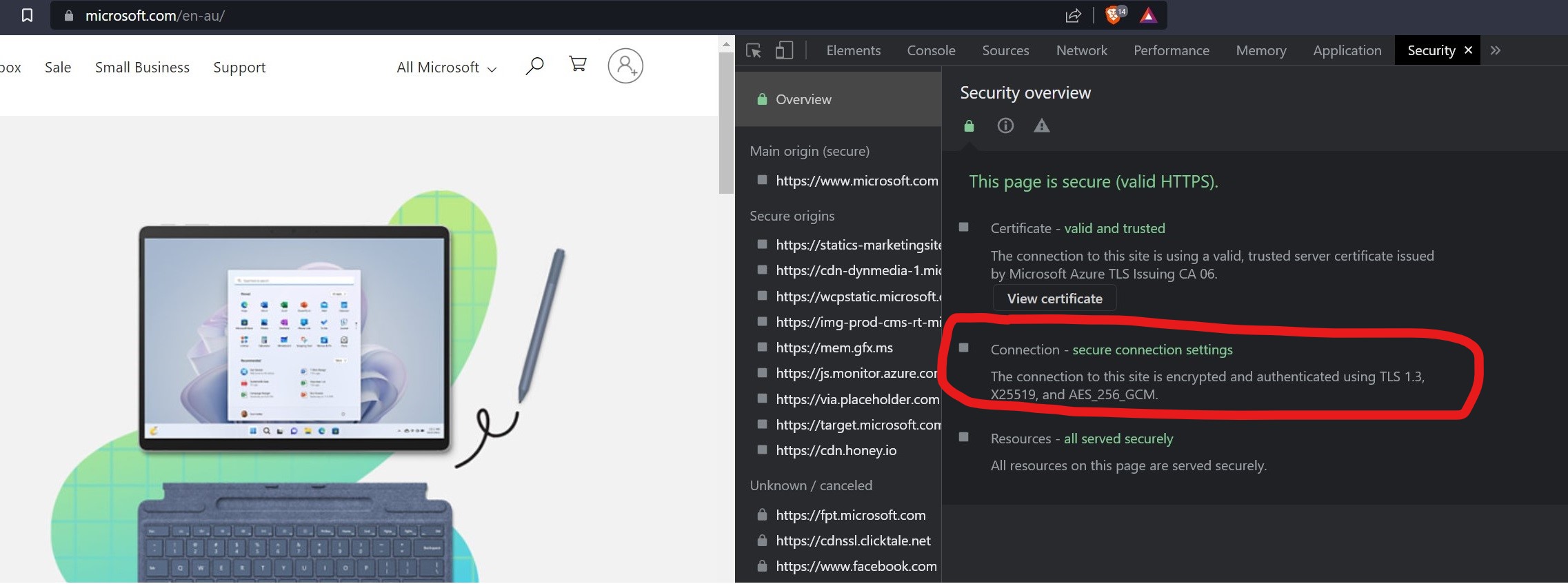 Image by
Image by
To set up a connection, the client device and the web server must do ‘TLS handshakes’ in which the devices agree on the encryption algorithm and cryptographic keys to be used for the connection. Each web browser implements TLS differently - e.g. Firefox uses NSS and Chrome uses BoringSSL.
The ‘fingerprinting’ is based off the beginning part of the TLS Handshake, where the client device sends information, such as:
- TLS version it supports (e.g. TLS 1.3)
- Cryptographic algorithm it supports (e.g. NSS, BoringSSL)
The first part of the TLS Handshake forms the fingerprint: that is, if the fingerprint matches any known bad devices, the server terminates the connection (and stops the bad actor from accessing the website).
HTTP/2 fingerprinting works in a similiar way, which uses the information sent as part of setting up a connection via the HTTP/2 protocol. As part of setting up the connection, the client will send ‘frames’ that contain unique info about the device (e.g. SETTINGS, HEADER, WINDOW_UDPATE). These can then be used to fingerprint the device.
Unfortunately, open-source technology exists that can bypass TLS and HTTP/2 fingerprinting using headless browsers - e.g. via puppeteer. This makes TLS and HTTP/2 fingerprinting alone an inadequate technique to fingerprint bad actors.
4. Device fingerprinting
Device fingerprinting is a more sophisticated method to uniquely identify devices, by building on top of CFP and TLS fingerprinting techniques to build a more comprehensive fingerprint for a device. Generally it involves identifying ‘legitimate devices’ and then excluding traffic from unknown/risky devices.
In addition to CFP fields, additional attributes/signals are used in the fingerprinting process, including:
- WebGL fingerprinting - e.g. Hash, version, unmasked vendor
- User agent of the web browser
- Screen resolution and size of the screen
For example, in the case WebGL fingerprinting, it takes advantage of the physical differences in each GPU. Tiny differences in each GPU will mean it will render the webGL image slightly differently. This in turns will generate a unique webGL hash.
 Your WebGL fingerprint is tied to your GPU!
Photo by Nana Dua
Your WebGL fingerprint is tied to your GPU!
Photo by Nana Dua
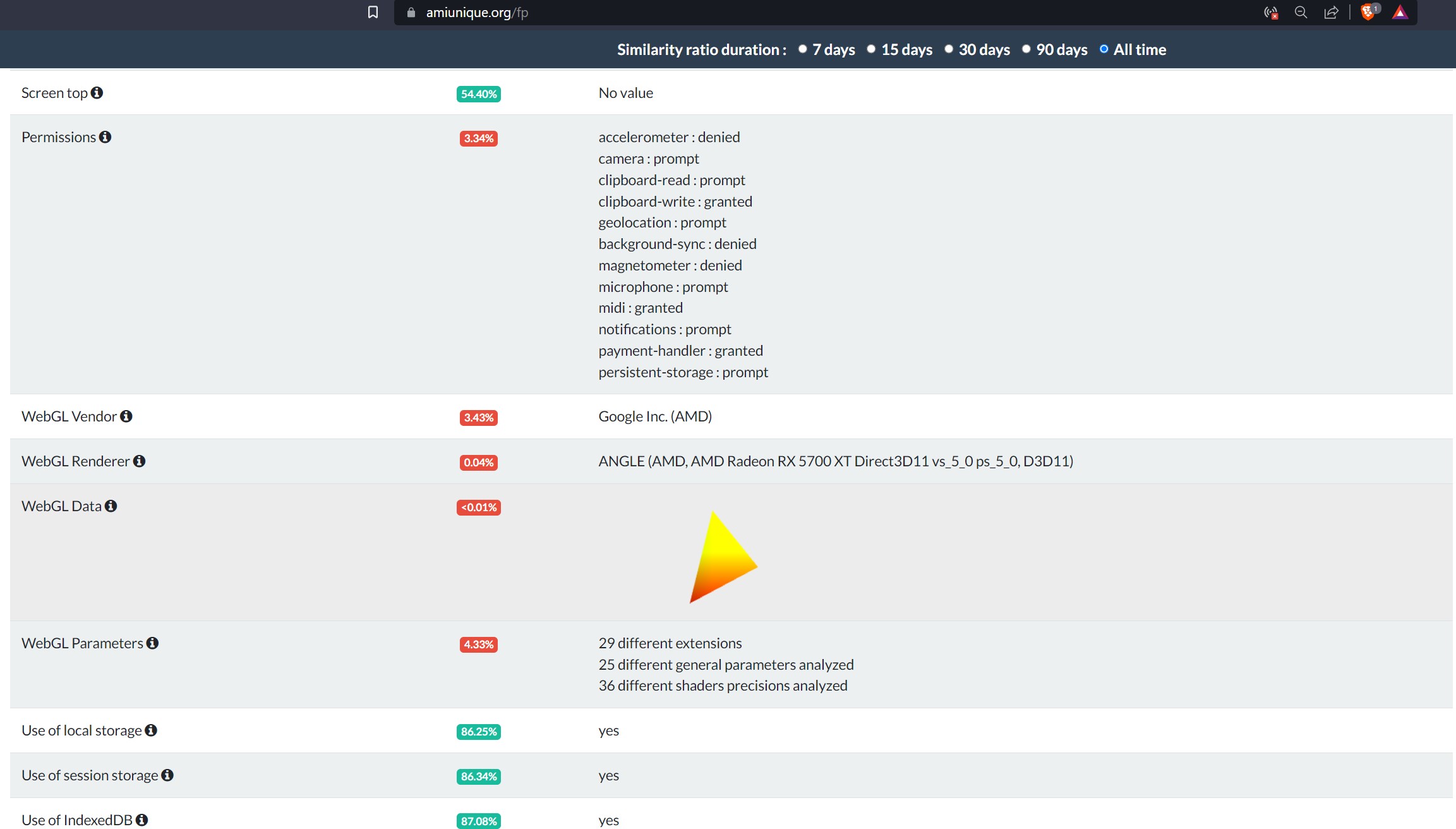 You can see that less than 0.01% of total devices have the same WebGL fingerprint as my device
You can see that less than 0.01% of total devices have the same WebGL fingerprint as my device
In addition to the canvas and WebGL fingerprints, the above attributes/signals are used as ‘features’ in the machine learning training process. The ‘target’ variable in this case is whether a login/session is a legitimate user or not. To further enhance the efficacy of the ML training process, each signal is assigned different weightings.
For example, there is more emphasis placed on a WebGL match, as it is a more precise attribute with a lower chance of non-unique matches. In contrast, web browsers are less accurate, as a user may often update their web browser (e.g. the latest Chrome version).
However, like CFP and TLS fingerprinting, many open-source technologies exist to distort the fingerprinting and in some cases even generate fake fingerprints!
5. Traffic Pattern Fingerprinting
As mentioned earlier, the previous fingerprinting methods can be bypassed by sophisticated automated attackers masking or distorting some of the signals they send to websites.
Furthermore, if attackers know the website uses device fingerprinting, they can just ‘replay’ that legitimate fingerprint. That is, it can deliberately try to send traffic to the website using a legitimate fingerprint’s signatures and ‘pretending’ to be legitimate!
Anecdotally, at work, I have seen some hilariously poor attempts of replays. In one case, an attacker tried to change their fingerprint to an iPhone device, but left the screen resolution at 3840 x 2160 pixels. I didn’t know iPhones had such large screens!

However, when done correctly, attackers can hide their attacks in legitimate traffic which makes device fingerprinting less effective. The solution to counter this is traffic pattern fingerprinting.
The idea is the pattern of the traffic of a website is fingerprinted. If a traffic doesn’t conform to this pattern, it generally is indicative of a cyber attack.
This type of fingerprinting is a form of ML anomaly detection, which focuses specifically on significant increases to traffic from a baseline.
At it’s basic, it does the following:
- Identify what the ‘baseline’ of traffic is for a particular website
- Identify what percentage of traffic we expect from a particular device fingerprint
- If we see a significant increase of traffic for a particular device fingerprint, it is indicative of an attack. (e.g. If we expect 5% of traffic to have a particular device fingerprint and we notice 15% of traffic matches that fingerprint)
To build this baseline, however, we require using machine learning forecasting techniques. Currently, some of the most advanced ML forecasting models and tools can be found in GluonTS and Darts.
GluonTS is a library for probabilistic time-series modelling using deep learning (i.e. neural network-based machine learning), that includes many types forecasting models.
Darts is also a toolkit that includes many forecasting models, with a focus on non-deep learning models.
The main models supported by these libraries include:
-
DeepAR and DeepVAR
Created by Amazon, it uses a recurrent neural network (RRN) and long short-term memory networks (LSTM). It uses Monte Carlo sampling (and quantile loss) to do it’s probablistic modelling (i.e. gives you a range of possible future outcomes via prediction intervals).
The biggest strength is it can do parallel training on multiple time series datasets. When a model is trained on multiple time-series datasets, it learns the global characteristics of all the datasets which it will use to that further enhance forecasting accuracy.
-
Temporal Fusion Transformer (TFT)
TFT is a transformer-based neural network created by Google.
It is an attention-based neural network, which means it ‘mimics’ how the human brain focuses on certain bits of information while ignoring other bits. As a transformer model (like ChatGPT), it learns context and tracks relationships between sequential data (which is great for time series, as it is a sequential series of data points).
-
Prophet
Prophet is a Bayesian-based additive model created by Facebook. I explored this in depth in my previous blog on Electricity Forecasting.
-
ARIMA and XGBoost
These are more traditional ML algorithsm that have I explored this in depth in my previous blog on Electricity Forecasting.
-
Fast Fourier Transform (FFT)
FFT is a statistical algorithm that uses Fourier series for forecasting. Interestingly, algorithms like Prophet also have a Fourier component to capture seasonality. Unlike deep learning, it is more intuitively easier to understand.
For the purposes of this blog, I will focus my discussion on FFT.
 Image by Burak The Weekender
Image by Burak The Weekender
Fast Fourier Transform
In a nutshell, fourier transform is a way to represent a time series as a frequency rather than as a function of time. Basically, the idea is to get how often a time series data repeats itself over selected measurement periods - e.g. weekly, monthly, yearly.
FFT is an algorithm that is a variation of fourier transform that is designed for much faster computation and ideal for machine learning on very large datasets (e.g. web traffic data).
For example, in the context of web traffic, it is possible to check for the following measurement frequencies:
- Baseline traffic repeats daily (e.g. 5pm is busier than 3am)
- Baseline traffic repeats weekly (e.g. weekends busier than weekdays)
When you identify the cyclical frequencies, you can use that to extrapolate into the future (i.e. forecast) what the future cycles will look like.
You can see in the below graph, that FFT takes the original time series data and represents it using a simpler cyclical graph.
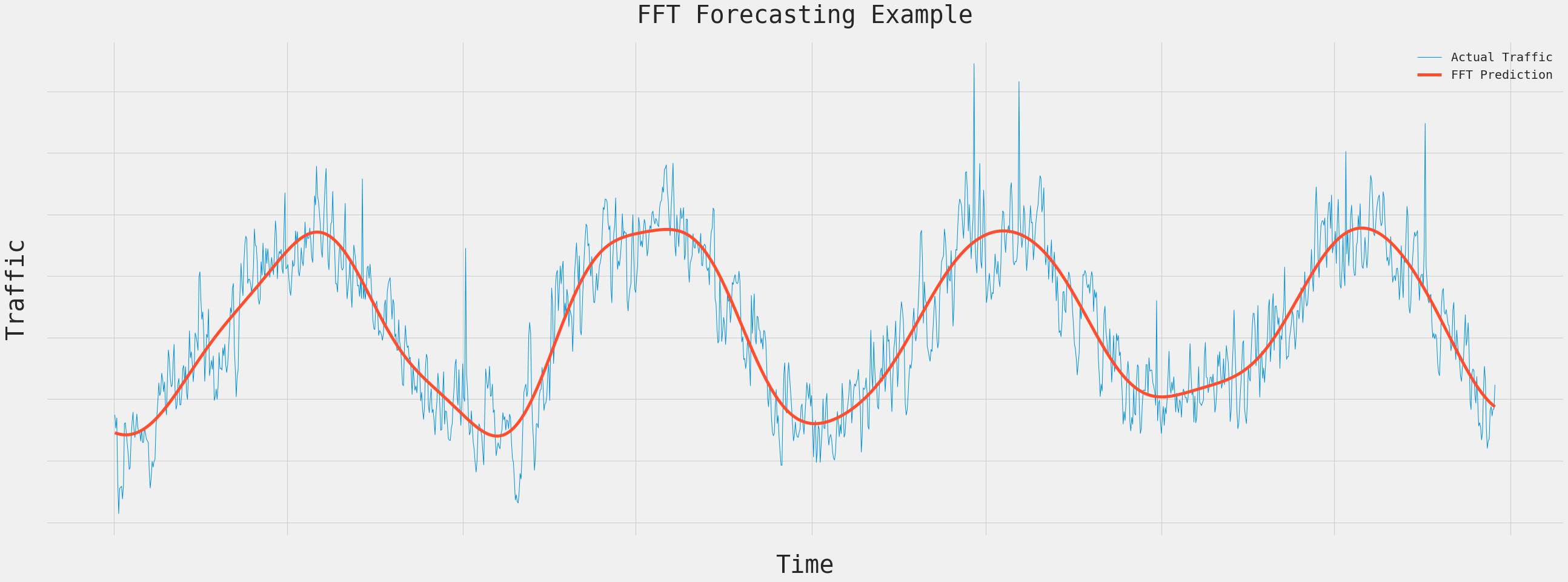 Example of a FFT - X axis is Time and Y axis is Traffic Volume
Example of a FFT - X axis is Time and Y axis is Traffic Volume
The idea is that once the baseline is determined via FFT, any traffic that is significantly above the baseline is a cyber attack. That is assuming cyber attacks do not repeat daily and weekly.
Going back to the graph, the orange boxes highlight examples of where traffic is significantly above the baseline. These are indicative of cyber attacks.
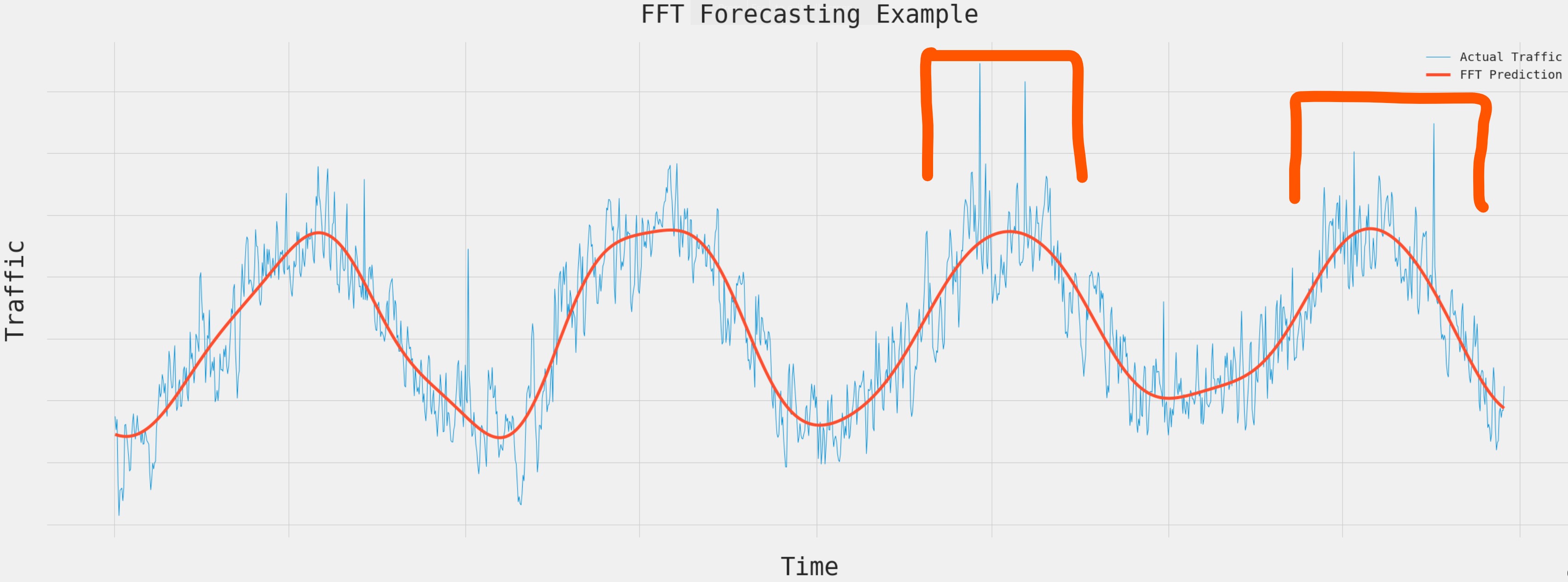 Example of a FFT - Orange boxes indicate traffic spikes
Example of a FFT - Orange boxes indicate traffic spikes
The downside of this form of pattern fingerprinting is it cannot identify ‘slow release attacks’. These are attacks which deliberately spread their traffic across a long period of time, so each particular moment only has a small amount of traffic.
Furthermore, if there is a cyber attack that is continuous going on for a long period of time, eventually the baseline will be distorted and take into account the increased traffic from the attack.
6. Behavioural Biometric Fingerprinting
Behavioural biometric fingerprinting (BBF) is a technique to fingerprint a user’s interaction with their device and the website. The main aim is to identify whether the behaviour is more like a human or like a bot.
The focus is on the physical and cognitive behaviour of the user, using metrics such as:
- Mouse clicks
- Keystrokes
- Touches on a touch screen
- Gyroscope (for mobile devices)
For example, bots have a tendency to interact with the webpage very quickly (i.e. super fast clicks) and very precise mouse movement (if any). In contrast, humans interact with a website organically, and might scroll a bit, stop, click around, then type something.
By setting certain analytics on behaviour of a user interacting with a website, we can fingerprint and determine which users are legitimate. Like device fingerprinting, BBF uses machine learning to analyse patterns to identify legitimate users vs botnet attacks.
This form of fingerprinting is passive and constantly working in the background as the user continues to interact with the website. Basically every single interaction with the website is recorded and sent as a signal to the detection system.
That is, every mouse click, scroll, letter typed, touch on the screen!
 Image by Gerd Altmann from Pixabay
Image by Gerd Altmann from Pixabay
However, as with all fingerprinting techniques, a sophisticated automated attack can bypass behavioural biometric fingerprinting by mimicing the behaviour of a human. It may, for example, deliberately do mouse clicks, touches or keyboard strokes that are random or out of place.
Examples of libraries that help do this include Ghost Cursor.
A method that counters against mimicking bots is using honeypot elements on a webpage. These are HTML elements which are invisible to the naked eye (i.e. humans), but bots can see them. When bots start clicking on these elements, it is indicative that they are not humans!
Conclusion
Hopefully this blog gives you a bit of a flavour on how fingerprinting works and how it helps protect against cyber attacks!
Defending against cyber attacks is an ongoing process and as attacks become more sophisticated, the methods used to defend against them must become better as well!
