What is event-driven architecture?
Event-driven architectures, is a type of design philosophy where the focus is processing a series of ‘events’.
Unlike traditional systems where only the current ‘state’ of data is known, every step within an event-driven process is stored in an ‘event store’, creating an immutable list of events.
The benefit of an immutable event history is that you can always go back and see exactly what steps were taken to get to where you are now. Immutability is achieved by only appending new events and not modifying existing events. You can then ‘time-travel’ or replay past events to re-create the current state of the data.
Another benefit of this architecture is processing only occurs when an event occurs. This is excellent for ‘serverless’ cloud-native architectures, as previously discussed in my other blog post.
In a nutshell, event-driven architecture is:
Event -> Do Something -> Output Something
Events occur from multiple sources:
-
Events that are the direct consequence of a user action
-
Events that are the consequence of something happening in external systems or the passing of time
-
Events that are the direct consequence of other events
Event-driven architecture has many similiarities to blockchain technology; however, the biggest difference is that blockchain has a strong emphasis on ‘trust’ that the list of transactions is the source of truth.
This article will discuss how to leverage serverless cloud computing even further with event-driven architecture and what all these parts mean in a bit more detail.
 Photo by Markus Spiske on Unsplash
Photo by Markus Spiske on Unsplash
Why event-driven architecture?
An event-driven architecture offers several advantages, such as:
-
Asynchronous and Parallelisation - runs can be done independent of each other. For example, having one run for each customer ID, rather than a batch of customer IDs. That way, if a customer ID fails, the entire system doesn’t grind to a halt. Aysnchronous also allows you to control the flow of the data a very granular level, so it doesn’t overload the target system (e.g. with queues, buffers).
-
Decoupled - each stage of the system doesn’t need detailed knowledge of the whole system, and therefore does not have tight/heavy coupling. This allows each compnent to be independently updated and deployed, even on a ‘live’ system, as the rest of the system doesn’t need to be taken down for maintenance.
-
Scalability – Each component of the system can be independently scaled up and down to meet demand
-
Error handling - Each event can be ‘replayed’ and even retries can be built into the system. This error handling provides resilience that a monolithic system would struggle to do, as it would not make sense to rerun an entire system just to fix 1 row of data.
Nuts and Bolts of an Event-driven Architecture
The event is the core of this architecture and starting point and also serve as the ‘input’ to the event-driven function. At a minimum it needs to provenance info about:
- The source of the event
- The context of the event
- The timestamp of the event
However, the input from the event won’t contain all the information needed, but will merely tell the function where to grab it. That is, it is a more a passive-aggressive way of notifying – just to let you know you have a new message in your voicemail, but if you want to know what, you need check your inbox.
 Hopefully the function won’t have this many inputs
Photo by Victor Barrios on Unsplash
Hopefully the function won’t have this many inputs
Photo by Victor Barrios on Unsplash
Importantly, the 'meat' of the content is from a permanent data store. This is generally a database (e.g. DynamoDB or NoSQL database) or object-store (e.g. S3 bucket).
For example, An AWS S3 event is triggered when a file lands in it, saying:
- Name of S3 bucket
- Name of file
- Time it landed in the S3
The function then needs to use that information and go read the actual file to figure out what the file is.
Stateless
In more conventional monolithic systems, every component sort of has an idea of what is going in other components and they may even share common variables/states.
For example, in a billing system, the number of invoices is saved as a global variable and any function just calls it to figure out how many invoices there are.
However, in event-driven architecture, each function is 'stateless' and 'ephemeral'.
Ephemeral means the function finishes running, anything it had in memory is lost forever (unless saved into a permanent data store)
Stateless means the function doesn’t know what its prior 'state' was - e.g. the last time it ran it missed 10 invoices.
State Engines
Instead of each function knowing about each other's 'state', an orchestrator generally exists, such a state engine, which keeps track of the entire system.

State engines sound fancy but generally day to day life has many workflows which are basically state engines.
A simple example of a state engine workflow would be:
- I go the kitchen
- I am in the kitchen – I go to the fridge
- I am at the fridge – I open the fridge door
- I see eggs, fish and ice-cream – I write it down on a piece of paper
- I leave the piece of paper on the counter
- I tell Bob the piece of paper has the list of ingredients, but I don’t tell him the ingredients
- Bob goes to the counter
- Bob reads the list and finds out the ingredients
 All this food talk is making me hungry!
Photo by Emre Can from Pexels
All this food talk is making me hungry!
Photo by Emre Can from Pexels
A Practical Example - my own pipeline
As mentioned earlier, I built a data pipeline using an event-driven architecture.
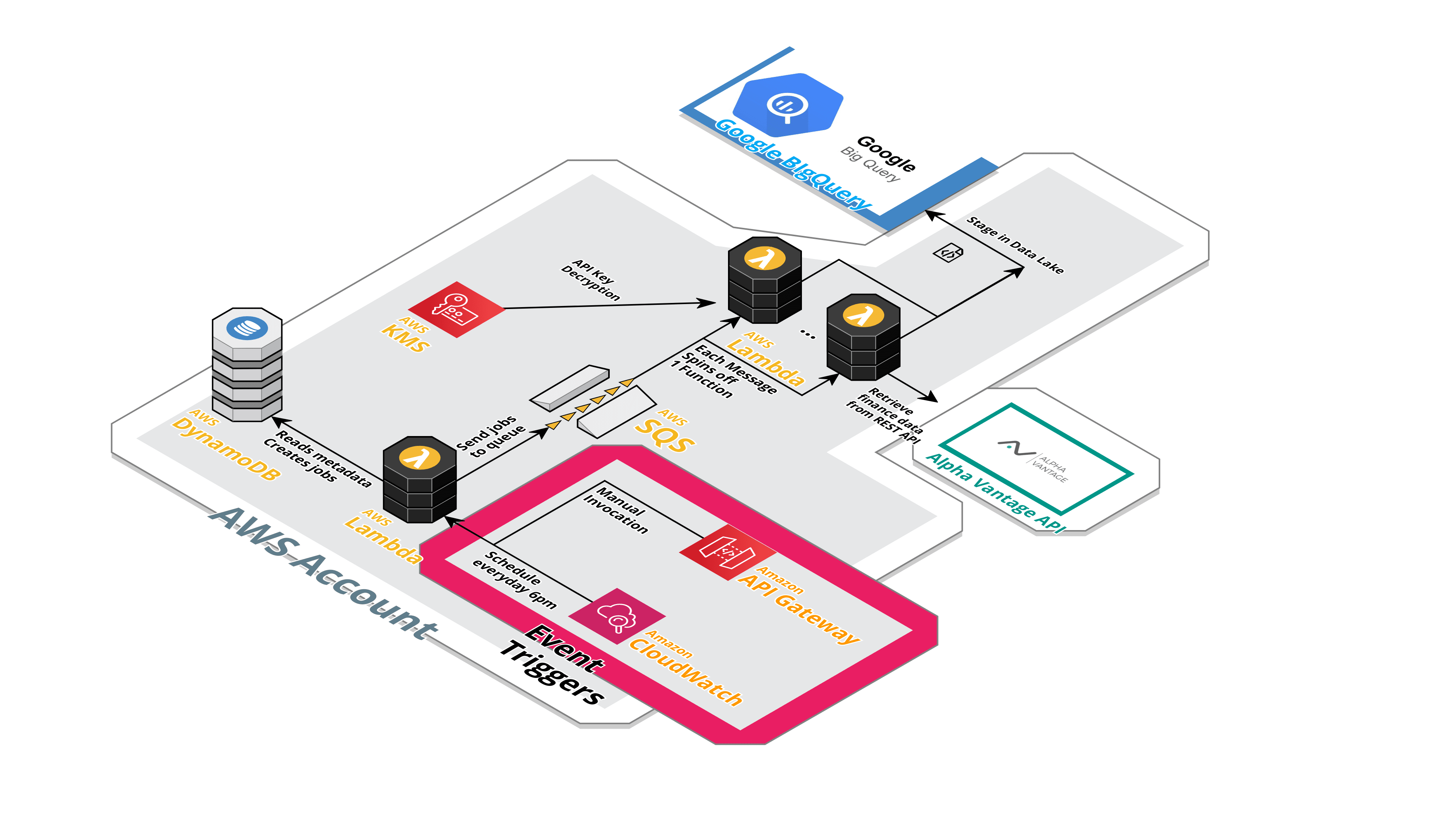
A brief description on how the pipeline works is as below:
-
Event trigger - either calling the API or CloudWatch cronjob
-
Event triggers the Lambda function to pull all the metadata from the DynamoDB table
-
The DynamoDB metadata contains a list of all the API calls required (e.g. AUD price, Bitcoin price, Microsoft NASDAQ share)
-
The Lambda sends message for every API call into the SQS queue
-
Event trigger - the created messages in the SQS queue spins off one Lambda per message
- Each Lambda calls the API with the message contents and either:
- success - saves CSV to S3 Landing
- fail 5 times - redirect to dead letter queue
-
Event trigger - the file created in S3 Landing
- Event triggers another Lambda to process the CSV and upload contents to Google BigQuery
The final goal is the data lake in Google BigQuery, where data analytics/science can be done using SQL and Python.
The entire data pipeline is event-driven, as each component of the pipeline only knows of the event input and the output. For example, the Lambda that retrieves the metadata from the DynamoDB has no knowledge of the downstreams Lambdas created from the SQS queue.
This architecture is scalable, as if the DynamoDB metadata table contains 1,000 commodities, the SQS queue will spin up concurrent/parallel Lambda functions. That way, there is no waiting around for one API call to finish before moving on to the next one.
As a side note, SQS queue throughput is relative to the number of messages it receives - for example, if 1,000 messages come in, it’ll likely spin up about 20-30 Lambdas at a time.
So why is event-driven so good for serverless?
What makes event-driven architecture so appealing for serverless cloud computing is nothing is running unless an ‘event’ happens. For example, you don’t need to have a web service running 24/7 if only 10 users download a file between 3-5am.
Another reason why it is so appealing is because each function operates independently and therefore you can scale out capacity easily. Scalability happens in two ways:
- Horizontally – number of functions
- Vertically – CPU and memory capacity of each function
Example of horizontal scaling: when you watch a streaming service, a function is spun up to fetch a link to the video and send it to your web browser. If 10,000 users login, 10,000 functions are spun up.
Example of vertically scaling: you increase the memory of each function so it can stream 2gb instead of 1gb
 Not this type of scale!
Photo by Pixabay from Pexels
Not this type of scale!
Photo by Pixabay from Pexels
The scaling is elastic in serverless because you don’t manage the infrastructure – if you need 1 million functions during peak time, you get 1 million.
The Glue - Queues and Pub/Subs
To help the functions in the event-driven pipeline talk to each other, there are usually ‘decoupling’ points. These generally are queues and publisher/subscriber (Pub/Sub) systems – basically components which pass messages from one part of the pipeline to another.
For example, in a data pipeline I set up:
- Messages are sent to a Queue or Pub/Sub system
- Each message contains the name of a company
- The queue or pub/sub systems then spins up a function for each message
- Each function then hits an API to fetch the latest stock price for that company
The ‘decoupling’ occurs because if in the future the source of these messages changes, the function that hits the API doesn’t need to know about it.
These components also act to relieve pressure between systems, so for example, overloading a database with an excessive amount of requests.
Pub/Subs
 You got Mail!
Photo by sue hughes on Unsplash
You got Mail!
Photo by sue hughes on Unsplash
Pub/Sub assist in decoupling even further because you can have a message sent to multiple systems. The sending system doesn’t need to know details of who the receiver is.
For example, I have a system that sends an error notification to a AWS SNS topic – which then ‘fans it out’ to an email inbox, a logging system and a text message. The system doesn’t need to know who the recipients are so if more recipients are added the system won’t need to know about them.
Queues
 Long queue!
Photo by Melanie Pongratz on Unsplash
Long queue!
Photo by Melanie Pongratz on Unsplash
Queues, like their real-life counterparts, contain messages that get processed – however, unlike Pub/Subs, queuing systems are not ‘fire and forget’ and also do error handling.
If a function fails to process the message, it will stay in the queue and another function will try again. That way you have more resilience – the analogy is like a queen ant sending a worker ant to fetch some food. If the ant fails to come back after 5 minutes, the queen ant just needs another ant. This will keep happening until an ant comes back with food.
The way pull-based queues work specifically for things like AWS Lambda (serverless functions) is analogous to a search and rescue team into a zombie-infested house:
-
A search and rescue drone is sent into the zombie house (function invocation)
-
Each drone only has a battery life of 60 seconds (function timeout)
-
If a drone completes its search, it will send an all-clear signal (function success)
-
If a drone is attacked, it will send an error signal (function error)
-
If the drone fails to relay an all-clear signal within 60 seconds, it’s presumed it failed because it no longer has anymore power
-
Unless a drone sends an all-clear signal, a new drone will keep being sent (pull-based queue)
That way, you only send the minimum amount of drones required to complete the search, but will keep sending drones until the search is complete. The 60 second battery also ensures no doubling up, so if the drone doesn’t complete the search in 60 seconds, it will shut down.
This type of function invocation is called ‘asynchronous’ - the queue isn’t sitting around waiting for the function to get back to it. If it fails to gets back within a specified time, it’ll just spin up another function.
To prevent infinite retries, if a message fails to process more than certain amount of times, you can redirect the message to a ‘Dead Letter Queue’. Like a post office in real life, if a message fails to process too many times, it goes into a queue which keeps the list of failed messages.
 Dead Letter Queue?
Photo by Zachary DeBottis on Pexels
Dead Letter Queue?
Photo by Zachary DeBottis on Pexels
There are more advanced techniques, such as First-in-First-Out queues and Visibility Timeouts in SQS, which I won’t dive deeper in this blog. But essentially these features help make sure a message at least processed message and for example you don’t copy the same file twice.
API Gateway
API Gateway is basically the 'front door' to your serverless application. Consistent with microservices architecture, the API is how users and other external systems generally interact with your system.
The major benefits of API Gateway are:
- It naturally integrates with other serverless AWS resources (such as Lambda)
- It is serverless - meaning, you only pay when the API is invoked. This is extremely useful if you have something that is only occasionally called.
- It scales automatically and well - if you need to have 1,000,000 calls to the API, it will scale horizontally.
- It has traffic management, authorization and access control, monitoring and throttling - this includes HTTPS, SSL Certificate integration with AWS Certificate Manager
- Caching - API Gateway caches results
 The Gateway
Photo by Pixabay on Pexels
The Gateway
Photo by Pixabay on Pexels
All these benefits make it a good choice in an AWS serverless architecture. For example, consistent with the event-driven architecture, you have a front-end REST API using API Gateway. Whenever a user calls it, the API Gateway integration with Lambda will run and retrieve something from the DynamoDB database.
The API Gateway then returns the data to the user. If another user requests the same thing, the caching will kick in and the response will be faster.
Cloud-native serverless architecture is good for event-driven scenarios, as its uncertain how many users will call the API on a day. Therefore, allocating capacity/infrastructure to an unknown amount of calls a day would be difficult to manage.
Navigating the Maze of Microservices
AWS X-Ray
As you can imagine, if you have so many events and components going off, it will spiral out of control very easily without decent logging.
Fortunately, there is AWS X-Ray.
AWS X-Ray is a service that helps you visualise and trace your various serverless components interacting with each other. There are many monitoring tools out there, but AWS X-Ray is (relatively) simpler to integrate and plus it has integrations with AWS Lambda, SNS, SQS, API Gateway.
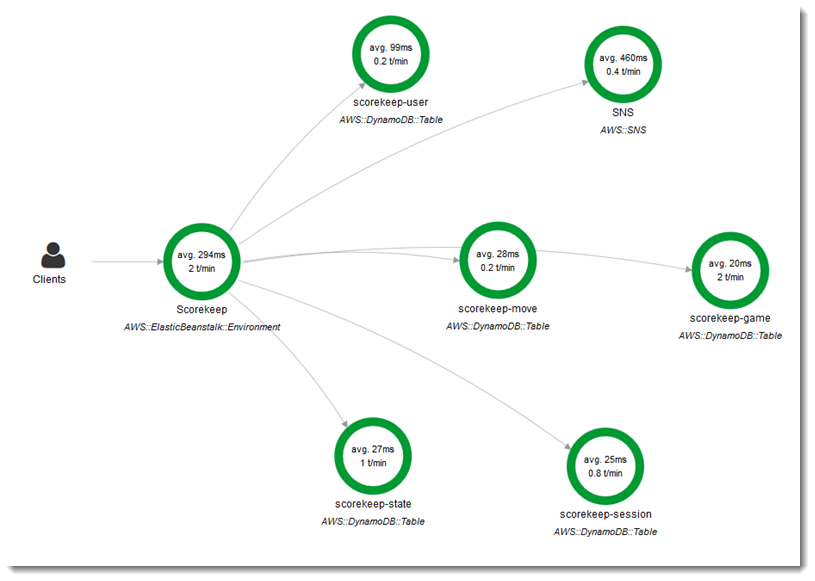 Example AWS X-Ray Visualisation from AWS Sample Application, ScoreKeep
Example AWS X-Ray Visualisation from AWS Sample Application, ScoreKeep
As you can see in the above visualisation, you can see the user invokes the Elastic Beanstalk web application, which subsequently invokes the various other components in the 'microservice' architecture (e.g. SQS, DynamoDB).
A common pattern in navigating these microservices is having a Correlation ID. Correlation IDs are basically an identifer that groups a request end-to-end through the microservices pipeline. For example, in the above visualisation, when a user invokes the API, all the subsequent events happening afterwards all get the same correlation ID.
That way, if you need to do debugging, you can trace through where it went wrong.
AWS CloudWatch for Monitoring
Dashboards are a great way to capture a bird’s eye view of the entire pipeline.
You can set it up using CloudWatch Insights and dashboards to create monitoring dashboards like so:
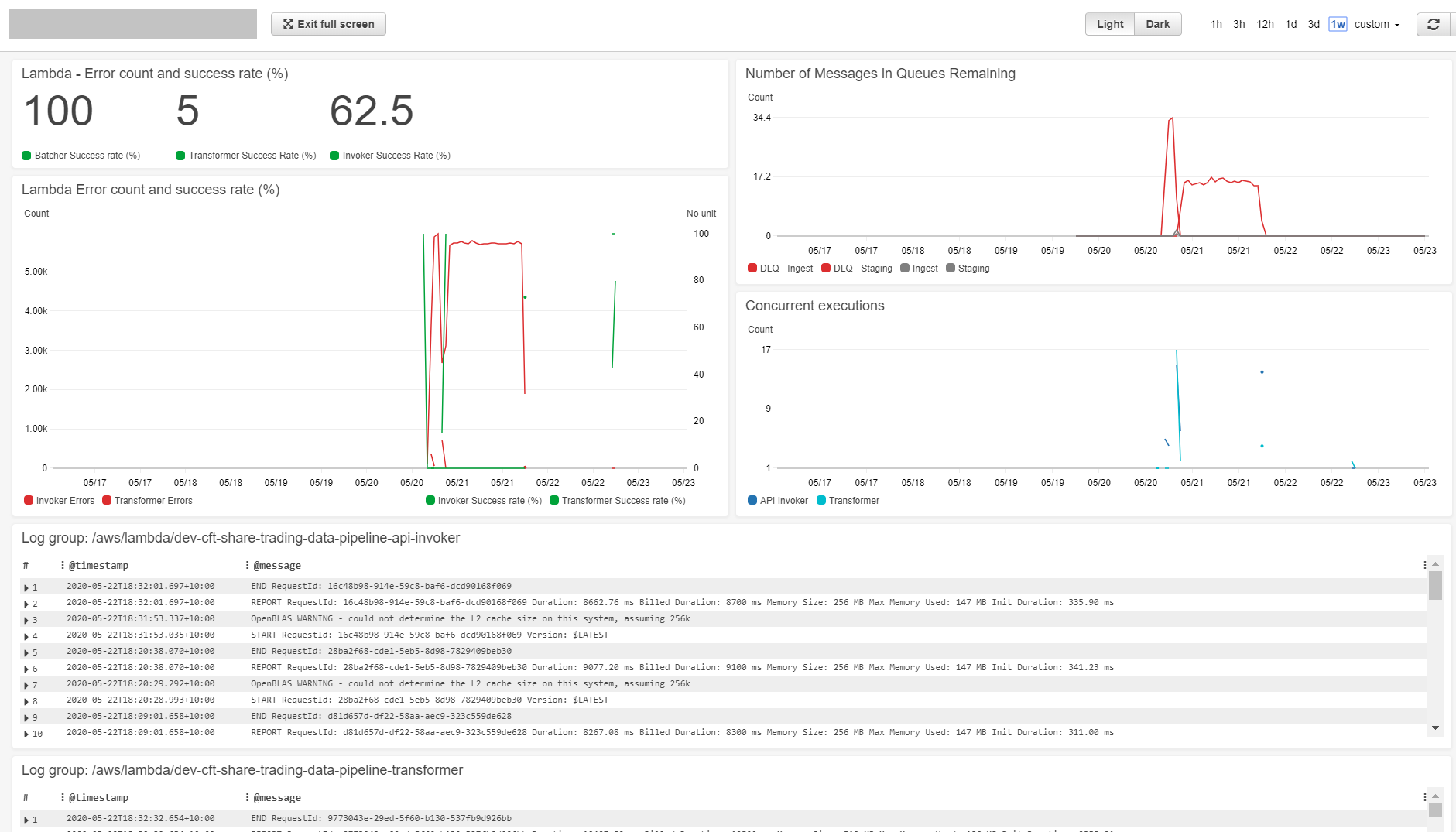 My CloudWatch dashboard, using AWS CloudWatch
My CloudWatch dashboard, using AWS CloudWatch
Using this dashboard, I can monitor:
- number of concurrent functions are running at any time in the pipeline
- the error rate and which parts are failing
- detailed output logs if I need to debug
Having this bird’s eye view is very important, because you want to be able to track what is happening across all the components of the pipeline at once.
Building Effective Cloud-Native Serverless Pipelines
As part of my journey in building cloud-native serverless pipelines, I've put together a checklist I include in my git repositories. It is a collation of many AWS best practice resources and the markdown format makes it easy to include in a git repository's README.md.
Closing Thoughts
Hopefully that gives a bit of a flavour event-driven architectures and designs. As long as serverless cloud computing grows, I think event-driven designs will become more prevalent.
 Wonder if the Matrix used event-driven architecture…
Photo by Markus Spiske on Pexels
Wonder if the Matrix used event-driven architecture…
Photo by Markus Spiske on Pexels