Serverless Data Pipelines
In the age of cloud, there's many use cases where you don't even need to keep constant machines running 24/7 - you just pay what you use for!
This is where serverless and 'Function-as-a-service' comes into play - you build up what you need and only pay for it when it runs! This is potentially big savings - if you keep a server running 24/7 just so you can run a pipeline every 5 minutes, that's over 23 hours of unnecessary uptime!
So what exactly is 'serverless'?
'Serverless' is really just a fancy way of saying 'someone else manages the servers, sets up the services and I just pay to use the service.' It takes a lot of the heavy lifting of infrastructure out, such as scaling, network security, storage capacity etc. In fact, this very website is being hosted on a 'serverless' technology!
 This very website is being hosted on AWS’s S3 service - no need to manage any servers, load balancers etc!
This very website is being hosted on AWS’s S3 service - no need to manage any servers, load balancers etc!
Cool, but why does it have to do with big data?
Back in the day, moving data around was an expensive exercise - you needed massive servers, had to pay for those servers in advance. If you used up all the compute on your server cluster, then you were kind of stuffed (sorry, but copying that 1 billion row table will have to be a weekend job).
Serverless computing gets rid of one of those massive headaches - scaling! Instead of paying for a massive server cluster, you just pay what you use. Your pipeline could use as little as 0.0002 of a CPU to 10,000+ CPU - all automagically done by the cloud service provider.
Data integration using a serverless stack
I actually had a requirement to get some data into the cloud and do some data analytics/science. My biggest headache was I didn't want to pay to keep a server on 24/7 just to download a few MBs of data everyday. The solution? AWS serverless computing!
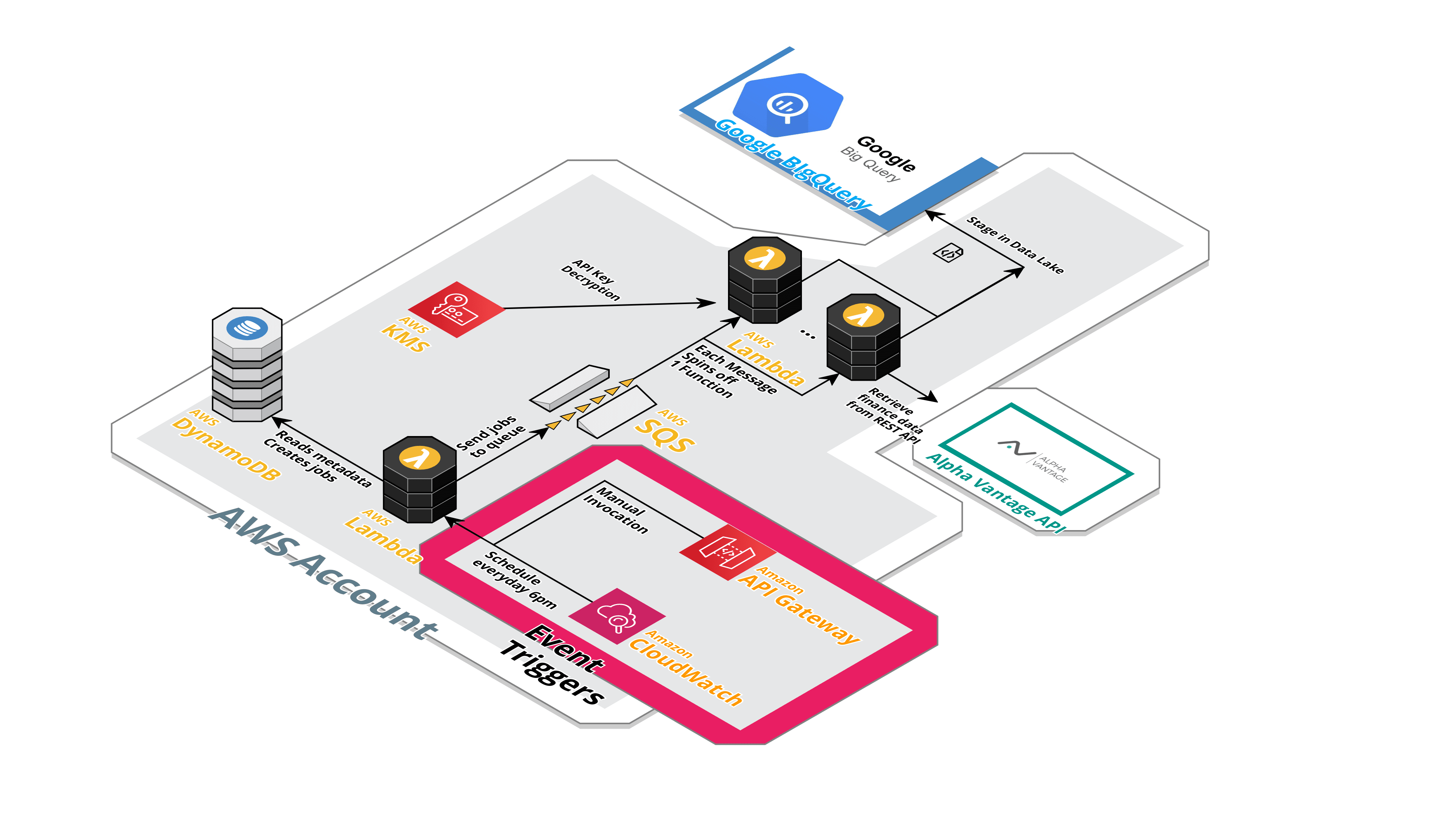 Using serverless offerings, I built out a data pipeline without a single server!
Visualised by http://cloudcraft.co
Using serverless offerings, I built out a data pipeline without a single server!
Visualised by http://cloudcraft.co
Essentially the serverless data pipeline has the following components:
- API Gateway - 'Front-door' of the pipeline. Lets you kick off the pipeline.
- DynamoDB - keeps the metadata that drives the pipeline. You add what jobs you want to run in the DynamoDB NoSQL table and it automagically works!
- SQS and SNS - messaging and queuing systems that 'glue' the various pieces together. Decouples the components so they don't need to worry about how to talk to each other!
- Lambda functions - the workhorse of the pipeline. It runs all the Python scripts needed to hit the REST API, grab the data and save it as a CSV in S3, as well as ultimately upload it to BigQuery
- S3 data store - keeps the ingested data at low costs ready for consumption/transformation later!
The beauty of this pipeline is you just keep adding jobs to the metadata and it'll spin up as many Lambda functions needed! Say if I added 50 jobs into the metadata table, then the queue will have 50 jobs and spin up 50 functions!
All running concurrently and without the hassle of scaling out!
Light on the wallet too!
Being quite frugal when it comes to cloud costs (don't want to get a $1000 surprise bill), serverless suits me great!
Using the budget estimator in http://cloudcraft.co (which by the way is what I used to draw the architectural diagram), it works out to be less than $1 a month!
In case you are wondering why on earth Lambda costs are $0, remember that AWS has a forever free tier of 1 MILLION lambda function requests per month!
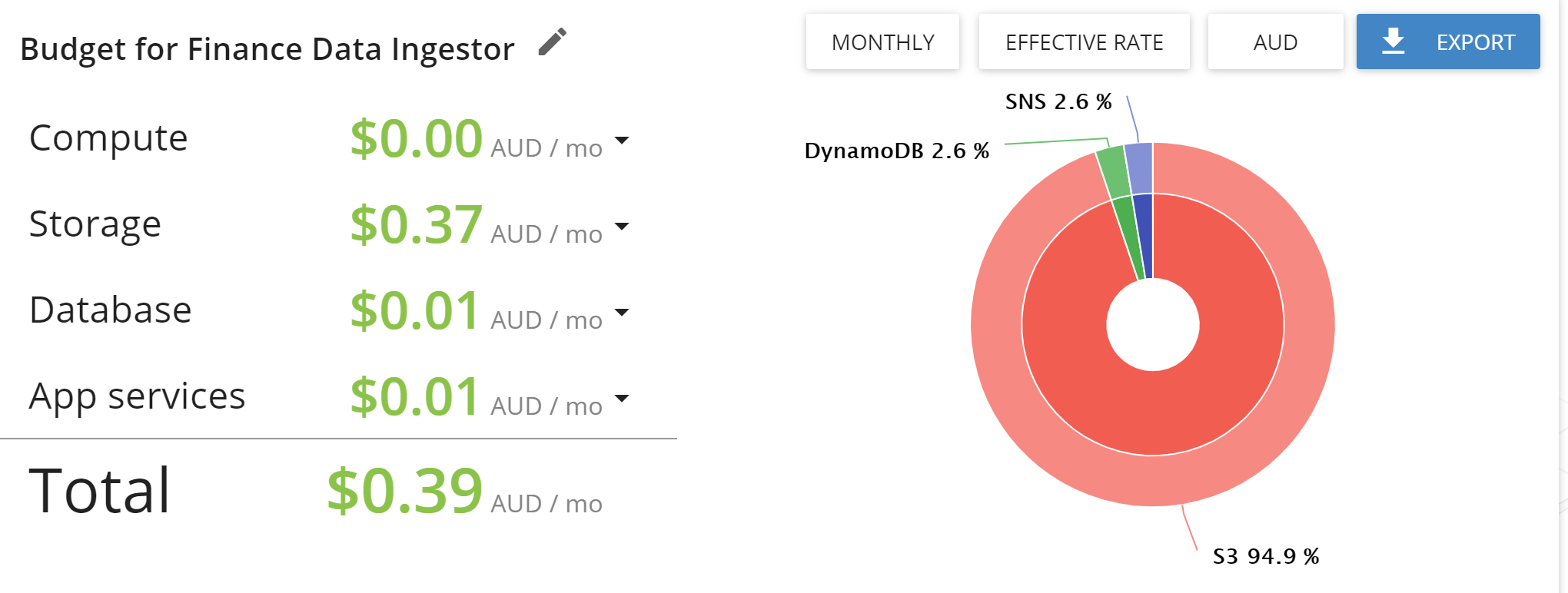 Woah that is light on the wallet!
Woah that is light on the wallet!
Data Analytics using 'Serverless' Technologies
In this day and age, Software-as-a-Service is becoming a good alternative to many legacy systems. Rather than having a SQL Server or Oracle Database cluster that is always on, you can only a more serverless offering. You only pay for each SQL query you run (or how much data you analyse).
There are a quite a few options out there, such as AWS Athena, AWS Aurora Serverless, but one that particularly stood out to me was Google BigQuery. Running on Google Cloud Platform (GCP), it is a described as a 'serverless, highly scalable, and cost-effective cloud data warehouse designed for business agility'.
What makes BigQuery so awesome is, like Snowflake, it runs in your web browser and gives you the same processing power as a massive data warehouse cluster (e.g. Teradata)!
 Google BigQuery - gives you massive data warehouse performance from your own laptop
Google BigQuery - gives you massive data warehouse performance from your own laptop
Getting started on BigQuery was simple - once the data is in, you are good to go! You start doing SQL queries and it all works! No provisioning of servers, no capacity issues - you just focus on your SQL!
Price-wise, BigQuery works perfectly for me - first 1TB scanned and first 10 GB storage is free each month. I don't think I'll be hitting anywhere close to 1TB any time soon...
How to get Data into BigQuery from AWS
Google BigQuery has client libraries (essentially SDKs) that directly integrate with Pandas Python. Pandas is a popular data library for Python, in which many data engineering projects use.
An example of using the SDK is as follows:
As you can see it is quite easy to get a Pandas DataFrame into BigQuery, and you don’t even need a ORM library (such as SQLite).
The tricky part is creating a Lambda Layer that lets you run the Google Cloud library in an AWS Lambda. For reference, here’s an AWS guide on how to do it.
Closing thoughts
I now have a website and a data pipeline all running in the cloud without me ever having to worry about servers! Of course you have way more control if you spun up your own containers and virtual machines in the cloud, and there's defnitely many use cases for doing that.
But until I need to process another 1 billion rows, I think the humble Lambda function and GCP BigQuery will do for now :)
I guess because I use AWS and GCP, technically that qualifies as a multi-cloud solution right?